Why Decentralize Facebook
October 17, 2010
Last week, I saw The Social Network. I enjoyed it as a movie (like everyone else, it seems), but it also made me unhappy, because it reminded me what a misdirected force Facebook is in danger of becoming (or already is). As most people realize, Facebook centralizes too much power; unless it changes course, this will be its undoing. I hear cheers from some in the audience, but it’s the users who will suffer along the way.
I’ll start with a quote from writer Jessi Hempel, reviewing the movie from the perspective of someone who claims to knows Mark Zuckerberg personally:
The real-life Zuckerberg was maniacally focused on building a web site that could potentially connect everyone on the planet. As early as 2005, he told me, “It’s a social utility and what makes it work will be ubiquity.” [Fortune]
To a first approximation, that’s the same as my goal of many years: building a system to connect everyone on the planet. But I don’t think it can possibly work if it’s a centralized system, with one organization controlling it to any substantial degree. Facebook may have 500m users, but it’s not going to get to 5b users until it’s a truly decentralized, open platform like the Internet and the Web.
More importantly, it wont get to the point where we can, in good conscience, require or assume our fellow travellers on this planet use it, as we generally can with email, the Web, and the telephone network. Some communities (eg schools) are requiring people use Facebook, and I’m not the only one who finds that scary and offensive.
Of course, Mark Zuckerberg is a smart guy. Wired reports him saying:
I don’t think the world is going to evolve in a way that there is just one big site. I think it is going to be that there are going to be a lot of really great services and we are helping to get it there. I think people are always a little skeptical when something grows to something big, but I think you need to look at what it is doing.
And he’s not the only one. When Google made their first attempt to replace email with Wave, they knew it would have to be decentralized, with them just being one of many equal hubs.
When I was younger, I loved decentralization because it got us out from under the control of authorities I didn’t respect. I think that particular fire may have gone out for me, but I still see the need: if we’re going to build the kind of universally shared apps the planet needs (and Facebook dreams of), they have to be built on an open, decentralized platform. Otherwise there is no way they’ll be able to reach even as far as the Web does now.
In a perfect world, I would now sketch out how to build a decentralized version of Facebook. But I seem to have too much else to do right now. So, at very least, that will have to wait for another day.
I can say that it would be built using linked data. I came to linked data as a good way to build global scale shared/social apps, and I still think it’s the best approach. There are some more details to work out, though. Sadly, I haven’t come across any promising funding or business models to support that work. Decentralized businesses don’t have market lock-in and $100m+ exits.
It may be Diaspora will do it. I’m confident before they get very far they’ll have to re-invent or adopt RDF, and eventually the rest of the SemWeb stack. I haven’t yet looked at their design. It may also be Facebook itself will do it. (The fact that Zuckerberg still controls the company, instead of investors, makes it somewhat more likely.)
I suppose, after saying all this, it’s on me to show how SemWeb technology actually helps. Or is that obvious?
Edited to Add: I got a private question about my claim that facebook can’t scale to 5b users, so let me expand on that a little. I see two things stopping them:
- A branding, and look-and-feel problem. Some people hate facebook, without even knowing why. Some people find the site awkward and difficult. This is going to be true of any site; I think the only way around this is to provide for multiple brands with multiple user interfaces. In theory, facebook could do this themselves, much like car manufacturers have multiple “makes”: Cadillac and Chevy are just product lines from the same company, but people’s feelings are directly mostly at the product line.
- A trust issue. Some communities (including some governments) will, quite rightly, refuse to trust facebook to operate in the way they want. It’s possible facebook can find a way to address this concern as well, with special contracts, and even special data centers. For instance, it wouldn’t be impossible for them to build a facebook cluster for CIA internal use, in a CIA facility, subject to full CIA controls, but still somewhat interoperable with facebook at large. But I wouldn’t hold my breath waiting for that to happen, either. I’m not sure how it will play out when teachers ask their students, and their parents, to use facebook.
So, that’s not an ironclad argument that they can’t grow to 5b, but that’s what I’m thinking.
Explaining Linked Data
June 8, 2010
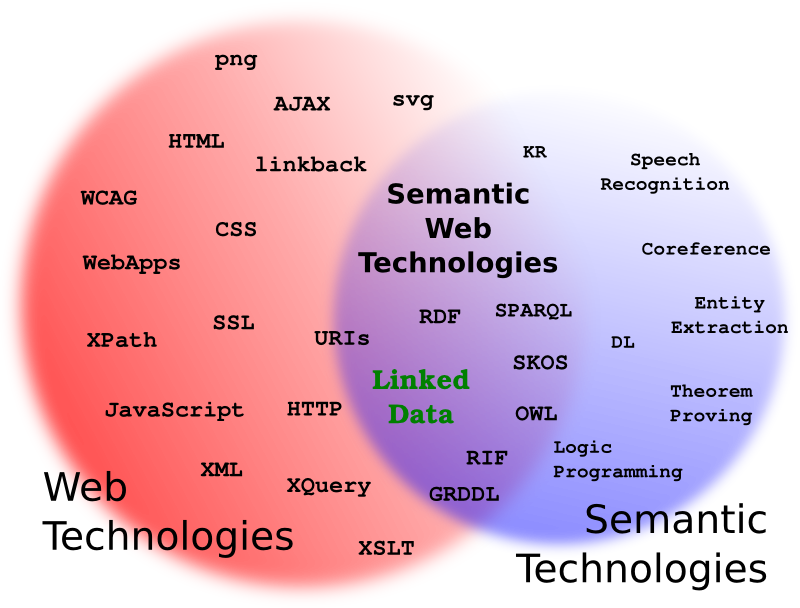
I’m going to try explaining linked data again, tonight, at the Cambridge Semantic Web Gathering. I will attempt to keep it simple, while still covering the important details. We’ll see how it goes.
My slides, for people who want a peek ahead of time, are here.
ETA: Thanks to Marco Neumann, there’s a video of my talk. I’m pretty happy with it. Also, my Venn Diagram slide, which you’re welcome to re-use with credit.
From JSON to RDF in Six Easy Steps with JRON
June 4, 2010
Sometimes, if you stand in the right place and squint, JSON and RDF line up perfectly. Each time I notice this, I badly want a way to make them line up all the time, no matter where you’re standing. And, actually, I think it’s pretty easy.
I’ve seen a few proposals for how to work with RDF data in JSON, but the ones I’ve seen put too much burden on JSON folks to accomodate RDF. It seems to me we can let JSON keep doing what it does so well, and meanwhile, we can provide bits of RDF which can be adopted when needed. Instead of pushing RDF on people, allow them to take the parts they find useful.
In thinking about it, I’ve come up with six things RDF can do that are not standard parts of JSON. These are things one can do with JSON, of course, but not in any standard way. My suggestion is these bits of functionally be provided in an RDF-compatible way (as I detail below), so that the JSON world and the RDF world can start to really play well together.
I’m interested to hear what people think of this. Blog comment, email to sandro@hawke.org (maybe cc semantic-web@w3.org?), or catch me in the halls at SemTech. I expect this general topic of RDF-meets-JSON will be discussed at the RDF Next Steps workshop, and if the stars line up right, maybe we can get a W3C Recommendation in this space in the next year or so. Let’s call this particular proposal JRON 0.1 (Javascript RDF Object Notation), not “Sandro’s Proposal”, so I can be freer to like other designs and be properly neutral.
Step 0: Start with ordinary JSON
In general, JSON and RDF are very similar, although they are usually described using different terminology. Of course, they both have strings and numbers. They both have way of encoding a sequence of items: arrays in JSON, lists in RDF (some details below). The main structuring is around key-value pairs, which JSON calls an ‘object’. In RDF we call it the “subject” and focus on its connection with each key-value pair; the three together form an RDF triple.
The point here is that ordinary JSON structures correspond to an important subset of RDF. The don’t exactly match that subset because RDF uses namespace, as detailed in step 5 below. The other steps below show the ways in which JSON is a subset of RDF. If one takes all the steps here, using JSON with these conventions, one has full RDF.
So, here are the steps. Steps 1-3 are pretty simple and not very interesting. They address everyday concerns in data processing. Steps 4-6 may be a little more surprising if you’re not familiar with RDF.
Step 1: Allow Extended Datatypes
Why: For datatypes, JSON only has strings, numbers, booleans. Sometimes people want to store and manipulate other datatypes, such as dates, or application-specific datatypes.
How: RDF uses XML’s datatype mechanism, where data values are conveyed as a pair of items: a lexical representation (a sequence of characters) and a datatype identifier (a sequences of characters which happens to be a URI). Each datatype is a mapping from strings (lexical representations) to values; the datatype identifier tells us which datatype is to be used to interpret this particular representation.
In JRON, we represent this pair like this:
{ "__repr": "2010-03-06",
"__type": "http://www.w3.org/2001/XMLSchema#date" }
You can put this as a value in a list or in a key-value pair, just like a string or number.
RDF doesn’t restrict which datatypes are used. Some recent standards work selected this list as the set people should implement.
Personally, I’m not sure users need to be able to extend datatypes. I see dates being important, but otherwise I’m not convinced. Still, it’s in RDF, and I like compatibility, so it’s here.
Step 2: Allow Language Tags
Why: When you have text available in several different languages, language tags provide a way to select which of the available strings, if any, matches the language preference of the user.
Also: Text-to-speech systems can handle text better if they know which natural language to use in pronouncing the text.
How: RDF allows language tags on string literals. In JRON, we use a pair like this:
{ "__text": "chat",
"__lang": "fr" }
Commentary: Personally, I’ve never liked this bit of RDF. I feel like there are better architectures for handling language tagging. But there was a vocal community that felt this was essential, so it’s in the standard. I gather some people like it, and I haven’t seen a good counter-proposal.
Step 3: Allow Non-Tree Structures
Why: Sometimes your data is not tree structured. Sometimes you have an arbitrary directed graph, such as when representing a social network.
How: In RDF, an arbitrary “node id” is available for making non-tree structures. We can do the same in JRON, saying any object may have a node id, and if it does, the object is considered the same as all other objects with the same node id. Like this bit JSON saying my friend Eric and I both know each other:
...
{ "foaf_name": "Sandro Hawke",
"foaf_knows: { "__node_id": "n102" },
"__node_id": "n334" }
...
{ "foaf_name": "Eric Prud'hommeaux",
"foaf_knows: { "__node_id": "n334" },
"__node_id": "n102" }
...
In the above example, the objects representing me and Eric are given node ids, and then those node ids are used to make the links to each other. We could also do this with only one node id, but we still need at least one:
{ "foaf_name": "Sandro Hawke",
"foaf_knows: { "foaf_name": "Eric Prud'hommeaux",
"foaf_knows: { "__node_id": "n334" },
"__node_id": "n334" }
Okay, those were the ordinary three things to add to JSON. Here are the interesting three:
Step 4: Allow Cross-Document Structures
Why: Sometimes, there is useful, relevant data available on the Web but it’s not part of the current JSON document. We would not want all the Web pages in the world to be gathered into one big Web page; similarly, it’s good to keep data in different documents. But that shouldn’t stop us from easily combining the data, and keeping the links intact.
How: RDF allows IRIs (unicode web addresses) to be used as node identifiers. They are like node ids, except they work across multiple documents; they are globally unambiguous identifiers, and systems can use Web protocols to dereference them to get other useful information.
In JSON, we can do this:
{ "foaf_name": "Sandro Hawke",
"__iri": "http://www.w3.org/People/Sandro/data#Sandro_Hawke"
}
Commentary: So why do we still need __node_id? Because sometimes it’s a pain to make up a good IRI. Some people prefer to always use IRIs, avoiding node_ids in their data, and that’s fine.
Step 5: Put Keys in Namespaces
Why: When data is coming from different sources across the Web, it’s not practical to get all the sources to agree on all the terminology. Instead, by using Web addresses (URLs/IRIs) as our keys, we allow individuals and organizations to make their own decisions. They can decide how much to share their vocabularies, and they avoid accidental name collisions. The web address also provides a handy link to documentation, community sites, schemas, etc.
How: It’s awkward to use a whole, long http IRIs everywhere, so as in many RDF syntaxes, JRON has a prefix expansion mechanism, like this:
{ "foaf_name": "Sandro Hawke",
...
"__prefixes": {
"foaf_" : "http://xmlns.com/foaf/0.1/"
}
}
Here the key “foaf_name” gets expanded into “http://xmlns.com/foaf/0.1/name”, which serves as a unique-on-the-Internet identifier for a particular conceptualization of names.
Commentary: Although I’ve left it almost to the end, this is the one mandatory part of this proposal. All the other elements are only present when required by the data. The null JRON document is: {“__prefixes”:{}}
Others have suggested this part can be optional, too, by having a set of standard prefixes for a given API. I’m not entirely opposed to that, but I’m concerned about how those defaults would be communicated in practice.
Also, I’m not sure there’s consensus on what character to use in the short name: should it be foaf_name, foaf.name, foaf:name, or what? The mechanism here is that you can use whatever you want: the __prefixes table keys are matched longest-first. If there’s an entry with an empty string, that provides a default namespace.
Step 6: Allow Multiple Values Per Key
Why: Sometimes it makes sense to have more than one value for some property. For instance, as it turns out, I have more than one friend. I could use a single-value ‘list-of-friends’ property, but sometimes it makes more sense to use a ‘friend’ property that has multiple values. In particular, if we’ll be learning who my friends are from multiple sources, and we were using lists, what order would we put the resulting combined list in?
How: We still just use JSON lists, but we indicate that the order does not matter, so the values can be merged arbitrarily:
{ "foaf.name": "Sandro Hawke",
"foaf.knows: { "__values": [
{ "foaf.name": "Eric Prud'hommeaux" },
{ "foaf.name": "Dan Brickley" },
{ "foaf.name": "Matt Womer" }
]}
}
Closing Thoughts
That’s it. Those are the six things that RDF does that normal JSONdoesn’t do. Did I miss something?
The API I’m imagining (but haven’t built yet) would have a few
features like:
- jron_reprefix(tree, desired_prefixes)
- Returns another JRON tree with all the prefixes matching the ones provided here. If you’re going to use foaf, for instance, you probably want to set a prefix like “foaf.” for foaf, so your code can expect it.
- jron_merge_nodes(tree) and jron_treeify(tree)
- convert a tree (suitable for transmitting) from/to a graph (suitable for use in memory
- jron_use_native_type(tree)
- Would convert all the __type/__repr objects into suitable local objects, if they exist. Maybe even date/time objects, if there’s a suitable library installed for those.
One technical issue for RDF folks:
Should JSON arrays be considered RDF Lists or RDF Sequences? Perhaps they default to RDF Lists but there can be an option flag in the top-level object:
{ ...
"__json_array_is_rdf_seq": true
...
}
When that flag is absent or false, arrays would be considered RDF Lists. My sense is no one needs to use both. Maybe soon we’ll know if RDF Sequences can finally be deprecated.
The Why and How of Linked Data
March 22, 2010
I’m just past halfway through nine consecutive days of all day meetings, clustered around the W3C’s semi-annual Advisory Committee meeting. When this series started, I didn’t have any particular responsibilities, beyond attending. But then John Sheridan had to canceled his trip, and I was tapped to stand in for him on panels at both the AC meeting (this morning) and FOSE tomorrow.
My slides don’t stand on their own very well, but here they are anyway. There might be video of the FOSE talk, later. And if you’re in Washington, by all means, drop by!
1. Why linked data is important for government open data initiatives. This was for a panel showing how Linked Data is being adopted, in various ways, in various industries, for an audience (W3C staff and member representatives) who were, perhaps, tired of hearing about the promise of the Semantic Web.

2. How To Do Open Data (in 10 minutes). This is for an audience of federal IT managers/vendors who are mostly unfamiliar with the concept of RDF.

RDF meets NoSQL
March 9, 2010
On Thursday, I have 20 minutes to address 200 people (plus a video audience) at NoSQL Live … from Boston. My self-appointed mission is to start building bridges between the NoSQL community and the Linked Data/RDF/W3C community. These are two sets of people working on different problems, but it’s pretty clear to me they are heading in the same direction, in similar spirit, and could gain a lot from working together.
I’m organizing my talk around the question of standardization for NoSQL, and I’ll talk about W3C process and such, but the interesting part is where NoSQL touches RDF. So here are some of my thoughts on that, written for an audience already familiar with RDF. I’d love to get some feedback on the basic ideas now, to make my talk better.
-
While they both want to move beyond SQL, their reasons are different. I understand the key for NoSQL is:
- SQL doesn’t scale big enough. Once your read-write dataset gets too big for a single machine, you have to develop and maintain a messy sharding system. (But see below.) Sometimes it’s an economy/efficiency thing; if you don’t need ACID, a NoSQL solution might give you better performance on cheaper hardware.
Meanwhile, I see two big motivation for the RDF folks:
-
Decentralization. On the open Web, data comes from many different sources, mostly beyond your control. Everyone might be providing data to everyone, and no one has the authority to run a central database, ever if they had the technology and the iron.
-
Inference. Some people find formal semantics and well defined inference to be very useful. (How is this different from triggers and views? Good questions.)
-
There’s a freedom, a joy, and in some case enormous practicality to not having to pre-create your database schema. Nearly all NoSQL and RDF systems are schemaless or allow a fully dynamic schema. (But I understand most bigtable systems have fixed column families. That could be a problem in using a bigtable as an RDF store.)
-
Both tend follow Web Architecture, using HTTP and often using REST.
-
Reading about CouchDB and MongoDB (JSON document databases), as well as Neo4j (a graph database), I noticed an undercurrent about SQL being awkward to program against. I guess this is the O/R Impedance Mismatch, especially the structural differences. RDF’s design is very close to the relational model, so it doesn’t help on this front. Within the RDF community, however, there are some systems which attempt to partly bridge this gap, including node-centric APIs (which I happen to prefer, myself). I would also argue that duck typing closes the gap from the programming-language side.
-
I don’t see NoSQL going anywhere near linked data or having a vocabulary ecosystem. I expect it will want to, someday. Decentralization is a key difference in requirements.
-
I only see RDF dealing with inference. Why is this? My first thought is that the RDF community has a lot of AI roots, and the NoSQL community doesn’t. But maybe it’s about economics and motivations: formalizing the notion of inference makes it possible, in theory, to easily deploy very sophisticated data transformation (and making them complete before the sun goes out). At NoSQL scale, folks are much more concerned about techniques for being able to run even simple transformations (and making them complete before the power bill comes due). I note that AllegroGraph manages to be in both communities, with a very practical, high-performance Prolog element; I don’t know how parallel it is. A few RDF folks are working on using map/reduce. Presumably, with the rise of multi-core systems, even single-user inference engines will want to be made parallel.
-
How many of the reasons for NoSQL rejecting SQL also apply to SPARQL? Does the scaling issue apply? Actually, does the scaling issue really apply to SQL? Michael Stonebraker (more or less the Voice of God) claims automatic sharding can and should be done while still using SQL. Some people reply: Perhaps, but in Enterprise-Grade Open Source? Also, maybe “SQL” is a euphemism for ACID, and that’s really what doesn’t scale and/or is too expensive. Perhaps that issue needs to be settled before considering SPARQL? Actually, the state of ACID in SPARQL is an open issue right now; maybe NoSQL can inform that decision.
-
RDF is standardized. Some would argue it’s more standardized than SQL; that case will be stronger when SPARQL 1.1 is done. Here’s a diagram Steve Harris made, which I reformatted. “KV” refers to key-value stores, the simplest, most scalable kind of NoSQL database.
So… What does that all boil down to?
Bottom line: RDF could learn a lot from NoSQL about scaling and ease-of-programming; NoSQL could learn a lot from RDF about decentralization and inference.
Some closing questions, ideas….
Can someone make a SPARQL endpoint with Cassandra’s performance and scaling properties? I haven’t studied this idea much, but I’m afraid the static column families will make it impossible to get much performance without building the store for a particular set of SPARQL queries. But it could still be useful, even with that drawback. Or maybe some SPARQL endpoint is already there; has anyone really tried a comparative benchmark?
How does the SPARQL endpoint description and aggregation work compare to database sharding. Are there designs for doing it automatically?
RIF and the Semantic Web (slides)
November 5, 2009
This morning, I gave the keynote address (my slides) at RuleML 2009. I assumed the audience would be fairly familiar with rule systems and rule technologies, but not necessarily with RIF, the Semantic Web in general, or my sense of the future of the Semantic Web (for which RIF is important).
Those slides may be boring for some of you. The interesting new bits:
- I made a new diagram for the RIF dialects. During the talk, I presented it as a successive reveal: the chaos of rule system features, the BLD grouping, the PRD grouping, and the Core intersection. Here’s the final slide:

- I wanted to convey that the Semantic Web means real change, and I wanted emotional impact, so I took a shotgun approach and enumerated a list of likely data sources that was big enough to have some surprises for most folks; then I moved into a long list of things you could do with that data. Some things on the list were boring (having impact only by showing how long the list is), but some got the desired wide eyes and shocked sounds as people realized this just might happen. I think it went over well.
My list of types of data we’ll be seeing:
- From producers: product information
- From sellers: product and service offerings
- Customer support (instructions, upgrades, …)
- Social network (who you trust, who interests you)
- Personal information shared with friends
- Public records (financial, legal, political, …)
- Science (medical, environmental, economic, …)
- News, Blogs, Public photos, videos
- Event listings (performances, meetings)
- Review, opinions, product experiences, preferences
- Personal location, location history
- Financial transactions
Which led into my general scenario: you’re in a store about to buy something, but first you scan it with your phone and look up a little more information about it. What might you look up?
- Its price at other stores, nearby
- Its price for delivery, and how how long you’d have to wait
- Maybe: where it was made, and under what conditions
- Is it’s producer a good corporate citizen?
- Does its producer agree with your political views (uh oh)
- How many houses does its CEO own?
- Did your spouse/housemate just buy some? Or something like it?
- How your friends feel about this product
- How Consumer Reports (or some such service) reviewed it
- Product liability suits
- Endorsements
- Maybe: Payment for Endorsements
- For electronics: compatibility information
- For mechanical items: How repairable is it? MTTF, MTTR
- For food: nutritional information, health benefits and risks
- Demographics of this brand, these products
That’s all for now. I saw the Bellagio Fountain from my 29th floor
hotel room late last night, but I’d like to see it up close.
RDF 2 Wishlist
October 30, 2009
Here’s what I think should be standardized at some point, soon, in the Semantic Web infrastructure. These items are at various levels of maturity; some are probably ready for a W3C Working Group right now, while others are in need of research. They are mostly orthogonal and most can be handled in independent efforts. (I would lean against forming a single RDF Working Group to handle all of this; that would be slower, I think.)
To be clear, when I say “RDF 2” I mean it like OWL 2: an important step forward, but still compatible with version 1. I’m not interested in breaking any existing RDF systems, or even in causing their users significant annoyance. In some traditions, where the major version number is only incremented for incompatible changes, this would be called a 1.1 release. In contrast, at W3C we normally signal a major, incompatible change by changing the name, not the version number. (And we rarely do that: the closest I can think of is CSS->XSL, PICS->POWDER, and HTML->XHTML). The nice thing about using a different name is it makes clear that users each decide whether to switch, and the older design might live on and even win in the end. So if you want to make deep, incompatible changes to RDF, please pick a new name for what you’re proposing, and don’t assume everyone will switch.
This is partially a trip report for ISWC, because the presentations and especially the hallway and lounge conversations helped me think about all this.
Note that although I work for W3C, this is certainly not a statement of what W3C will do next. It’s not my decision, and even if it were, there would be a lot of community discussion first. This is just my own opinion, subject to change after a little more sleep. Formally the decisions about how to allocate W3C resources among the different possible standards efforts are made by W3C management guided by the the folks who provide those resources, via their representatives on the Advisory Committee (AC). If the direction of the W3C is important to you or your business, it may be worthwhile to join and participate in that process.
1. RDF and XML interoperation
There’s a pretty big divide between RDF and XML in the real world. It’s a bit like any divide between different programming languages or different operating systems: users have to pick which technology family to adopt and invest in. It’s hard to switch, later, because of all the investment in tools, built systems, educations, and even socially networks. (People who use some technology build social and professional relationships other people who use the same technology. Thus we have an XML community, an RDF community, etc. Few people are motivated to be in both communities.)
I think we should have better tools for bridging the gap, technologically, so that when data is published in XML, it’s easy for RDF consumers to use it, and when the data is published in RDF, it’s easy for XML consumers to use it.
The leading W3C answer is GRDDL, which I think is pretty good, but could use some love. I’d like to see support for the transforms being in Javascript, which I think is probably the dominant language these days for writing code that’s going to run on someone else’s computer. It certainly has a bigger community than XSLT. I’d probably support Java bytecode, too.
I would also like to see some way to support third-party GRDDL, where the transform is provided by someone not associated with either the data provider or data consumer. Nova Spivack gave a keynote where he talked about this feature of T2. They’re focused on HTML not XML, but the solution is probably the same.
Beyond GRDDL, I think there’s room for a special data format that bridges the gap. I’ve called it “rigid rdf” or “type-tagged xml” in the past: it’s a sub-language of RDF/XML, or a style of writing XML, which can be read by RDF/XML parsers and is also amenable to validation and processing using XML schemas. Basically you take away all choices one has in serializing RDF/XML.
I note the The Cambridge Communiqué is ten years old, this month. It proposed schema annotation as an approach, and that’s not a bad one, either. I haven’t heard of anyone working on it recently, but maybe that will change if the XML community starts to see more need to export RDF.
Amusingly, while I was talking to Gary Katz from MarkLogic about this, he mentioned XSPARQL as a possible solution, and I pointed out Axel Polleres (xsparql project leader) was sitting right next to us. So, they got to talk about it. XSPARQL doesn’t excite me, personally, because I don’t use either SPARQL or XQuery, but objectively, yes, it might solve the problem for some significant userbase.
2. Linked Data Inference
For me, an essential element of a working Linked Data ecosystem is automatic translation of data between vocabularies. If you provide data about the migration of frogs in one vocabulary, and my tools are looking for it in another one, the infrastructure should (in many cases) be able to translate for us. We need this because we can’t possibly agree on one vocabulary (for any given domain) that we’ll all use for all time. Even if we can agree for now, we’ll want this so that we can migrate to another vocabulary some time in the future.
Inference using OWL (and its subsets like RDFS) provides some of this, but I don’t think it’s enough. RIF fills in some more, but the WG did not think much about this use case, and there’s might be some glue missing. Maybe we can get WG Note out of RIF to help this along.
I’d like us to be clear about first principles: when you’re given an RDF graph, and you’re looking for more information that might be useful, you should dereference the predicate IRIs to learn about what kinds of inference you’re entitled to do. And then, given resources and suitable reasoners, you should do it. That is, the use of particular IRIs as predicates implies certain things, as defined by the IRI’s owner. The graph is invoking certain logics by using those IRIs. (Of course you can always infer things that were not implied, but as among humans, those “inferences” are really just guesses you are making. They have quite a different status from true implications.)
If this is put together properly, and the logics are constructed in the right form, I think we’ll get the dynamic, on demand translation I’m looking for. I imagine RIF could be very useful for this, but reasoner plugins written in Javascript of Java bytecode could be a better solution in some cases.
Some of my thinking here is in my workshop keynote slides, but later conversations with various folks, especially Pat Hayes and TimBL, helped it along. There’s more work to do here. I think it’s pretty small, but crucial.
3. Presentation Syntaxes
RDF, OWL, and RIF all have hideous primary exchange syntaxes and some decent not-W3C-recommended alternative serializations. I’m not really sure what can practically be done here that hasn’t been done.
At very least, I’d like to see a nice RDF-friendly presentation syntax for RIF. A bit like N3, I suppose. I did some work on this; maybe I can finish it up, and/or someone else can run with it.
OWL 2 has 3+n syntaxes, where n is the number of RDF syntaxes we have. Exactly one of those syntaxes is required of all consumers, for interchange. I’ll be interested to see how this plays out in the market.
4. Multi-Graph Syntax
Most systems that work with RDF handle multiple graphs at the same time. Sometimes they do this by storing the triples in a quad store, with the fourth entry being a graph identifier. This works pretty well, and SPARQL supports querying such things.
We don’t have a way to exchange multiple graphs in the same document, however. N3 has graph literals (originally called contexts), and there was some work under the term named graphs, which is kind of the opposite approach.
Personally, I don’t yet understand the use case for interchanging multiple graphs in one document, so I’m not sure where to go with this.
Hmmm. I guess RIF could be used for this. You can write RDF triples as RIF frame facts, and the rif:Document format allows multiple rulesets, each with an optional IRI identifier, in the same document. ETA: RIF also gives you an exchange syntax where you can syntactically put literals in the subject and use bnodes as predicates, if you want. But now you’re technically exchanging RIF Frames instead of RDF Triples.
5. RDF Graph Validation
When writing software that operates on RDF data, it’s really nice to know the shape of the data you’ll find. It’s even nicer, if software can check to see if that’s actually what you got. And if reasoners can work to fill in any missing peices.
I don’t exactly understand how important or unimportant this is. It’s closely related to the Duck Typing debate. Whatever mechanisms make duck typing work (eg exception handling, reflection, side-effect-free programming) probably help folks be okay without graph validation. But I think folks trained on C++/Java or XML Schema would be much happier with RDF if it had this
The easiest solution might be using rigid RDF. One could probably also do it with SPARQL, essentially publishing the graph patterns that will match the data in the expected graphs.
The most interesting and weird approach is to use OWL. Of course, OWL is generally used to express knowledge and reason about some application domain, like books, genes, or battleships. But it’s possible to use OWL to express knowledge about RDF graphs about the application domain. In the first case, you say every book has one or more authors, who are humans. In the second case, you say every book-node-in-a-valid-graph has one or more author links to a human-node in the same graph. At least that’s the general idea. I don’t know if this can actually be made to work, and even if it can, it risks confusing new OWL users about one of the subjects they’re already seriously prone to get wrong.
6. Editorial Issues
Finally, I’d like some portions of the 2004 RDF spec rewritten, to better explain what’s really going on and guide people who aren’t heavily involved in the community. This could just be a Second Edition — no need for RDF 2 — because no implementations changes would be involved.
I’d like us to include some practical advice about when/how to use List/Seq/Bag/Alt, and reification, maybe going so far as to deprecate some of them (IMHO, all but List). Maybe bring in some of the best-practice stuff on publishing and n-ary relations.
I understand Pat Hayes would like to explain blank nodes differently, explicitly introducing the notion of “surfaces” (what I would call knowledge bases, probably). Personally, I’d love to go one step farther and get rid of all “graph” terminology, instead just using N-Triples as the underlying formalism, but I might a minority of one on that.
ETA: Of course we should also change “URI-Reference” to “IRI”, and stuff like that.
Okay, that’s my list. What’s yours? (For long replies, I suggest doing it on your own blog, and using trackback or posting a link here to that posting.) Discussion on semantic-web@w3.org is fine, too.
Linked Government Data
September 11, 2009
A few weeks ago, I was drafted to replace José Manuel Alonso as W3C eGovernment Lead (in addition to my Semantic Web standards work). I’ve never worked with eGovernment before, but it turns out that the W3C group working in the area had recently resolved to:
identify ways for governments and computer science researchers to continue working together to advance the state-of-the-art in data integration and build useful, deployable proof-of-concept demos that use actual government information and demonstrate real benefit from linked data integration.
I wish they’d said that with fewer words, but, yes, I do know something about that.
So this week, I was in Washington, wearing a suit (but no tie — this was an O’Reilly crowd), attending the Gov2.0 Expo Showcase and the Gov2.0 Summit. It’s like a forest in spring after a fire, with wildflowers blooming everywhere, and grand, government proclamations about future growth. My overwhelming impression, from events on the stage, was that:
- the Federal government is undergoing a massive effort to begin systematically publishing machine-readable data, across all agencies, in a sustainable way, driven from both the top (Obama) and by all the grassroots awareness of the new technology;
- state and local governments also see the benefits, and some brave souls are leading the way, often with much success;
- there is an army of developers, commercial and hobbiest, open source and proprietary, waiting to develop mind-blowing (and genuinely useful) applications using this data.
I had a little re-adjustment panic, feeling like there was nothing interesting left to do. Like when you show up to help some friends move, and they’re already done and sitting around eating the pizza.
But there’s still lots to do. People who’ve been in Washington a long time assure me it will be many years before a significant fraction of the data is really being published, and, as we well know, getting the data released does not mean it’s easy to use. It’ll be a long time before we have stable feeds of accurate data using appropriate formats and vocabularies.
So how do we get there from here? What should the agencies start doing now, to help ease the transition, and get us there faster? And where, exactly is “there”?
(As if I would know? Well, it’s what I’m thinking about this week, so here’s my braindump, before it all gets swapped out for the weekend, and something else gets swapped in Monday morning.)
The Linked Data Ecosystem
Our goal, my goal, is to have a scaleable and robust platform for decentralized apps to share their data. Right now, we have a handful of decentralized apps (such as e-mail), but most social software (multi-user apps) runs off a single vendor’s server farm. Yes, youtube, twitter, facebook, google docs, flikr, and others have figured out how to make it work, and how to make it scale, but they still run the systems. We want all that functionality, but without any one organization being a bottleneck, let alone potentially behaving badly.
This goal, I should note, is considerably less compelling now than it was when many of us signed up, in some cases decades ago, since we now have an effective app distribution system (with modern web browsers), and a vibrant, competative, and healthy market for these individual centralized services. But some of us still would rather not trust facebook or google with too much of our personal and professional lives.
I suspect the government is best not relying on them too much, either.
Over the years, the Semantic Web community has been developing a set of techniques, based on open standards, for achieving these goals. They are not perfect, and they are not always polished, but most of them work well and the rest look pretty close.
-
Present all your data in as triples, building everything out of Subject-Property-Value statements. This roughly lines up with rock-solid technologies like relational databases and object-oriented programming, and new techniques, including JSON and terascale databases (Google’s BigTable app engine datastore, Amazon’s SimpleDB). The details are ironed out in RDF, a W3C standard first published in 1999, and then rearticulated with clarification in 2004.
When you use triples as your building blocks, you have to be more explicit about the structure of your data, and this eases accurate interoperation. The simplicity also supports metadata, reasoning about data, data distribution, and shared infrastructure even among disparate applications.
-
Use Web addresses (URLs/URIs/IRIs) to name things. Each thing that someone might need to refer to — cities, agencies, people, projects, items in inventory, websites, events, etc — should be assigned a universally unambiguous identifier (nothing else uses the same identifier), so that every source of data about that item can be merged, always knowing it’s the same item. It’s okay (and unavoidable, in some cases) to have multiple identifiers for some items; the important thing is to be able to use the same identifier, when we know it.
We use Web addresses to build these identifiers, because we already have a structure for making sure there are no unintended duplicates, and because it allows an important element of of centralization. Each time some organization mints a new web-based identifier, it gets the ability to provide (through its web server) some core data about that item. It’s not that their data will always be correct, but it provides a starting point, a seed around which a shared understanding of the item can grow.
-
Build for change and diversity, with backward and forward compatibility, and multiple views on the same data, knowing that the world changes, and our understanding of the world changes. (This needs its own article, but Why I Want RIF? covers the hardest parts of the territory.)
How Do We Get There?
The mood of the summit, and perhaps the mood everywhere near technology corners of the White House, seems to be one of ecstatic urgency. Folks seem to think everything can and should be done at a record pace, with crowd sourcing and agile development. The perfect is the enemy of the good. Get something good out there, then refine it. Fail early, fail fast. This is awesome…. but how do we iterate from here to a fully-evolved linked data ecosystem? And let’s not just assume the crowd will do all the right things.
There are two parts to the problem, and we can separate them, running them in parallel:
- Get more and more public data streams flowing.
- Make the data streams more and more usable.
There is a synergy between these two. As more data appears, more useful things can be done with it. As more good things are done with it, the incentives to release data become stonger. (Of course, some bad things will be done with it, too. But that’s a subject for another day.)
I don’t have any insights into part 1. That’s political, whether it’s workplace politics or national politics. I don’t know if there are any shortcuts. The case just has to be made, better and better, in all the right places, until the right stakeholders and decision makers and people who really do the work are convinced.
But part 2 can be crowd-sourced. It can be turned into a market, a community effort.
Supporting the Community Around a Data Source
People need to see what others are doing, and people doing good things need to be rewarded. People need to have some confidence they’ll be rewarded for doing good things. And mostly: the community needs to be arranged so that the more people participate, the better it gets. (See the video of Clay Shirky’s talk at the Summit about how to do this, in general.)
In this case, good things include:
- Clarifying what elements of the data feed mean
- Documenting the accuracy, methodology, etc, of the feed
- Finding and potentially correcting bugs in the data
- Developing software which somehow uses the data, and (1) sharing lessons learned in developing the software, (2) making the software available in various forms (web service, commercial download, open source, etc)
- Linking to related feeds
- Providing derived feeds, reformating, correcting, or otherwise improving or re-targetting this data
- Providing merged feeds, which process this data along with other data, to create something new
- Summary/Analysis feeds
- Review, commentary, support for all these related items
- Career and project-funding opportunities related to this feed
- Social events related to this feed
There’s lots more to be said here, but … deadlines are the antidote to perfectionism. So I’ll stop here for now. Comments welcome. If this stuff really interests you, please consider joining joining the W3C eGovernment Interest Group. (It’s an open group; W3C membership is encouraged but not required.)
Online Lending Libraries for Digital Media
August 23, 2009
Here are some things I want to do:
- Put my pictures of my latest family vacation on the web, where my friends and family can see them. Let my mother put her pictures of the same events there, too. Let me select some for my friends to see, and her select some for her friends to see. Know that the pictures will be there, safe, for as long as anyone in the family wants them to be.
- Put my movie collection on the web, so I can watch my movies wherever I happen to be, and so can my kids. If one of them is at a friend’s house, why should it matter if she remembered to bring the DVD, if the house has a good network connection?
- Borrow my friends’ movies and music from time to time. If I want to watch some old college favorite (let’s say Heathers), and I know my friend Keith has a copy, must I drive 20 minutes to his house to borrow his DVD? No, I want him to have it on his server, and let me borrow it. (Note that I’m not asking to make my own copy. What I want might or might not break some laws, but it seems to me that if I can legally borrow his physical DVD for a few days, I should also be able to legally borrow the bits on his DVD. As long as there’s still only one working copy at any point in time, I expect the MPAA wont be quite so furious with me.
- I want this copy-protection to be only advisory; if Greg borrows my copy, and somehow loses it or it breaks, I can just reclaim it. If he finds it again, his copy is an illegal one. There’s no need for security here (someone would just crack it anyway); I just want to make it easy for people who want to follow the rules to do so, and I hope the system would usually make it easier to follow the rules than to break them.
- I want this to be private. I’m talking about sharing with my friends here, not sharing with the world. I may not want the world looking through the family vacation pictures, and I don’t want strangers borrowing my movies if it’s going to prevent me from watching them. I certainly don’t want strangers copying movies I paid for if it’s going to make the MPAA apoplectic (as I’m sure it would).
I know: youtube, myspace, flickr and their less-popular but more-exciting rivals offer something like this. But I want it decentralyzed. When I say private, I mean private from everyone, including Google and News Corp and Yahoo/Microsoft. And when I say I want the pictures to be there, “safe”, more-or-less forever, I don’t just mean until some corporation decides to change its terms of service, or capriciously enforce some clause I never noticed.
I think we can do this.
Servers
The heart of any system like this is the servers, of course. I suggest that a few people in each cluster of friends would be willing to pay a few dollars a month for some managed web space. Imagine it as a locker, and they tell their friends the combination. Or a private island, and they give their friends the right to land, in their private jets. (Virtual private jets are free in this modern world.) It’s a web location where they and their friends can store their digital media, where it’s easy to access. (When users access these storage sites, I picture them generally not caring about location; I look for “Healthers” and it finds all the copies all my friends are willing to share — no need to specifically ask Keith. With this, redundancy should be convenient and encouraged.)
I picture the server software being pretty simple (web+db), and something any web hosting provider could offer with one-click installation. Like wordpress, etc, but even simpler. The point is that if you want your own locker/island, you could rent one for $5/mo (low end) to $50/mo (high end), from commodity providers.
The data would be stored encrypted, so the host computers and hosting services never get to see what bits are really stored. They can’t see the family pictures or hollywood movies, even if they want to, no matter their terms of service or pressure from the government.
(These secure network volumes already exist, in various forms, most famously Amazon S3. There’s no magic here, but we might want a few tweaks to the API, and there’s definitely a need to package it differently so that my mother can comfortable sign up for hers. Also, I think this would support a market for cheaper and less-reliable storage, since reliability could be provided by other means.)
Clients
The clients would be more than just browsers. They have to understand the media tagging and indexing, and handle the crypto. They’d probably offer discussion boards, and such, as part of the media metadata.
I’m imagining three different kinds of clients:
- A purely web-based client would allow users an experience very much like flickr and youtube. It could show ads, and it would know your encryption keys, but at least it wouldn’t be hosting the media data, so you could move from one to another without risk of losing your photos, music, and movies.
- A plug-in for a media player like VLC.
- A command-line, virtual-file-system client. This is the kind of thing I might hack together as a prototype, using fuse. All the lockers to which I have keys would appear as a big filesystem, and there would be some tools for searching and manipulating it. I could use my existing media players, unmodified.
That’s the gist of it. I have lots more details floating around in my
head. Does it exist already? Shall I go ahead and make a prototype
(in my copious free after-hours time)?
Why I Want RIF
July 9, 2009
RIF is done, more or less.
When I say “done”, I don’t mean “done” like toast in the toaster is done, when it’s just perfectly crunchy, without quite being dry or hard. And I don’t mean “done” like a hacking project which is done at that precise moment when it stops being more fascinating than sleep or food or sunshine. No, RIF is “done” like a term paper, the night before it’s due. It meets the requirements, more or less, and the time has come to ship it.
Of course, the W3C process favors quality over speed, so instead of turning it in and walking away, we’ll have to do several rewrites, to address the teacher’s comments. In this case, we have at least three rounds of that. In the first round (called “last call”, which started last friday), the “teacher” is anyone who feels like reading and commenting. Then comes “candidate recommendation”, when we try to get everyone to implement it and give us comments as they do. (This is where OWL 2 is now). Finally, we’ll ask for a high level review from all W3C member organizations, as they decide whether to promote it from Proposed Recommendation to a full W3C Recommendation.
But still, it’s done like that term paper. It’s turned in, and now we wait for the review comments.
So what is RIF good for, anyway?
The consensus, Working Group answer is 26 pages long and rather in need of some polish, so here’s my short answer. Here’s why I’ve spent the last five years working on it. (No need to cry for my lost youth, I did some other fun things during that time, too.)
We need RIF so that we don’t need standards any more.
If you’ve ever tried to use FOAF (arguably the most popular Semantic Web vocabulary), you may have noticed a little problem with representing names. Am I:
- [ foaf:firstName “Sandro”; foaf:surname “Hawke”], or
- [ foaf:givenname “Sandro”; foaf:family_name “Hawke” ], or just plain
- [ foaf:name “Sandro Hawke” ] ?
Who knows? How can anyone decide? It’s a mess.
And, of course, this problem is repeated everywhere. Every ontology has its share of coin-flip design decision — decisions where you have no overwhelming engineering reason to make one choice over another. And every problem space has, or will soon have, a vast array of ontologies addressing it from many slightly-different angles.
I want data providers to publish using whatever ontology they know and love.
I want data consumers to consume (use) data in whatever ontology they know and love.
I expect RIF to be the glue in the middle, behind the scenes, in a fuzzy ball of linked-data rule-engine goodness.
Imagine Jos publishes using foaf:firstName and foaf:surname. Imagine Chris publishes using foaf:givenname and foaf:family_name. Imagine Gary writes an app which looks for foaf:name data. As long as the right RIF rules are present on the Web, in the right places, this should work. People using Gary’s app should see the data from Jos and the data from Chris, even though Gary never knew or cared about the vocabularies they used.
Of course, there’s some question as to what those rules should say. In the US, the givenname and the firstName can be treated as the same. Meanwhile, in Japan, the family_name is the firstName! And if you try to split a name back into firstName and surname, do you use the last space (as in “Sarah Jessica Parker”) or the first space (as in “Hillary Rodham Clinton”)?
I think the solution is to accept that there may be multiple rulesets, suitable for different purposes, and they may not be perfect. I explored this space to some degree in a different context: XTAN associates some “impact” (which might be called “semantic damage”) with each transformation (or ruleset). I think that can work.
So, there are still some details to work out. I’m not presenting the solution here; I’m just explaining why RIF interests me. Now you know.
(And no, I don’t really think this will entirely obviate the need for standards, but I think it will significantly reduce that need, taking some pressure off, and shifting some more work to the machines.)

{kind=link}