Back to Blogging
June 16, 2017
As I remember it, about ten years ago, I started this blog for one main reason. I had just watched a talk from the CTO of Second Life (remember them, when they were hot?) about his vision for how to expand by opening up the system, making it decentralized. I thought to myself: that’s going to be really hard, but I’ve thought about it a lot; I should blog my ideas about it.
As I dug into the problem, however, I realized how many sub-problems I couldn’t really solve, yet. So I never posted. (Soon thereafter, Cory Ondrejka left the Second Life project, moving on to run engineering at Facebook. Not sure if that’s ironic.)
Now, what feels like several lifetimes later, I’m ready to try again.
This time the “industry darling” I want to tackle first is Uber. Okay, it’s already become widely hated, but the valuation is still, shall we say, … considerable.
So, coming soon: how to decentralized Uber.
GrowJSON
June 30, 2014
I have an idea that I think is very important but I haven’t yet polished to the point where I’m comfortable sharing it. I’m going to share it anyway, unpolished, because I think it’s that useful.
So here I am, handing you a dull, gray stone, and I’m saying there’s a diamond inside. Maybe even a dilithium crystal. My hope is that a few experts will see what I see and help me safely extract it. Or maybe someone has already extracted it, and they can just show me.
The problem I’m trying to solve is at the core of decentralized (or loosely-coupled) systems. When you have an overall system (like the Web) composed of many subsystems which are managed on their own authority (websites), how can you add new features to the system without someone coordinating the changes?
RDF offers a solution to this, but it turns out to be pretty hard to put into practice. As I was thinking about how to make that easier, I realized my solution works independently of the rest of RDF. It can be applied to JSON, XML, or whatever. For now, I’m going to start with JSON.
Consider two on-the-web temperature sensors:
> GET /temp HTTP/1.1
> Host: paris.example.org
> Accept: text/json
>
< HTTP/1.1 200 OK
< Content-Type: text/json
<
{"temp":35.2}
> GET /temp HTTP/1.1
> Host: berkeley.example.org
> Accept: text/json
>
< HTTP/1.1 200 OK
< Content-Type: text/json
<
{"temp":35.2}
The careful human reader will immediately wonder whether these temperatures are in Celcius or Fahrenheit, or if maybe the first is in Celcius and the second Fahrenheit. This is a trivial example of a much deeper problem.
Here’s the first sketch of my solution:
> GET /temp HTTP/1.1
> Host: paris.example.org
> Accept: text/json
>
< HTTP/1.1 200 OK
< Content-Type: text/json
<
[
{"GrowJSONVersion": 0.1,
"defs": {
"temp": "The temperature in degrees Fahrenheit as measured by a sensor and expressed as a JSON number"
},
{"temp":35.2}
]
> GET /temp HTTP/1.1
> Host: berkeley.example.org
> Accept: text/json
>
< HTTP/1.1 200 OK
< Content-Type: text/json
<
[
{"GrowJSONVersion": 0.1,
"defs": {
"temp": "The temperature in degrees Fahrenheit as measured by a sensor and expressed as a JSON number"
},
{"temp":35.2}
]
I know it looks ugly, but now it’s clear that both readings are in Fahrenheit.
My proposal is that much like some data-consuming systems do schema validation now, GrowJSON data-consuming systems would actually look for that exact definition string.
This way, if a third sensor came on line:
> GET /temp HTTP/1.1
> Host: doha.example.org
> Accept: text/json
>
< HTTP/1.1 200 OK
< Content-Type: text/json
<
[
{"GrowJSONVersion": 0.1,
"defs": {
"temp": "The temperature in degrees Celcius as measured by a sensor and expressed as a JSON number"
},
{"temp":35.2}
]
the software could automatically determine that it does not contain data in the format it was expecting. In this case, a human could easily read the definition and make the software handle both formats.
That’s the essence of the idea. Any place you might have ambiguity or a naming collision in your JSON, instead use natural language definitions that are detailed enough that (1) two people are very unlikely to chose the same text, and (2) if they did, they’re extremely likely to have meant the same thing, and while we’re at it (3) will help people implement code to handle it.
I see you shaking your head in disbelief, confusion, or possibly disgust. Let me try answering a few questions:
Question: Are you really suggesting every JSON document would include complete documentation of all the fields used in that JSON document?
Conceptually, yes, but in practice we’d want to have an “import” mechanism, allowing those definitions to be in another file or Web Resource. That might look something like:
> GET /temp HTTP/1.1
> Host: paris.example.org
> Accept: text/json
>
< HTTP/1.1 200 OK
< Content-Type: text/json
<
[
{"GrowJSONVersion": 0.1}
{"import": "http://example.org/schema",
"requireSHA256": "7998bb7d2ff3cfa2666016ea0cd7a379b42eb5b0cebbb1142d8f086efaccfbc6",
},
{"temp":35.2}
]
> GET /schema HTTP/1.1
> Host: example.org
> Accept: text/json
>
< HTTP/1.1 200 OK
< Content-Type: text/json
<
[
{"GrowJSONVersion": 0.1,
"defs": {
"temp": "The temperature in degrees Fahrenheit as measured by a sensor and expressed as a JSON number"
}
]
Question: Would that break if you didn’t have a working Internet connection?
No, by including the SHA we make it clear the bytes aren’t allowed to change. So the data-consumer can actually hard-code the results of retrieval obtained at build time.
Question: Would the data-consumer have to copy the definition without changing one letter?
Yes, because the machines don’t know which letters might be important. In practice the person programming the data-consumer could do the same kind of import, referring to the same frozen schema on the Web, if they want to. Or they can just cut-and-paste the definitions they are using.
Question: Would the object keys still have to match?
No, only the definitions. If the Berkeley sensor used tmp instead of temp, the consumer would still be able to understand it just the same.
Question: Is that documentation string just plaintext?
I’m not sure yet. I wish markdown were properly standardized, but it’s not. The main kind of formatting I want in the definitions is links to other terms defined in the same document. Something like these [[term]] expressions:
{"GrowJSONVersion": 0.1,
"defs": {
"temp": "The temperature in degrees Fahrenheit as measured by a sensor at the current [[location]] and expressed as a JSON number"
"location": "The place where the temperature reading [[temp]] was taken, expressed as a JSON array of two JSON numbers, being the longitude and latitude respectively, expressed as per GRS80 (as adopted by the IUGG in Canberra, December 1979)"
}
As I’ve been playing around with this, I keep finding good documentation strings include links to related object keys (properties), and I want to move the names of the keys outside the normal text, since they’re supposed to be able to change without changing the meaning.
Question: Can I fix the wording in some definition I wrote?
Yes, clearly that has to be supported. It would be done by keeping around the older text as an old version. As long as the meaning didn’t change, that’s okay.
Question: Does this have to be in English?
No. There can be multiple languages available, just like having old versions available. If any one of them matches, it counts as a match.
The Web is like Beer
March 11, 2014
Lots of people can’t seem to understand the relationship of the Web to the Internet. So I’ve come up with a simple analogy:
The Web is to the Internet as Beer is to Alcohol.
For some people, sometimes, they are essentially synonymous, because they are often encountered together. But of course they are fundamentally different things
In this analogy, Email is like Wine: it’s the other universally popular use of the Internet/Alcohol.
But there are lots of other uses, too, somewhat more obscure. We could say the various chat protocols are the various Whiskeys. IRC is Scotch; XMPP is Bourbon.
gopher is obscure and obsolete, …. maybe melomel.
ssh is potato vodka.
I leave the rest to your imagination.
Note that the non-technician never encounters raw Internet, just like they never encounter pure alcohol. They wouldn’t know what it was if it stepped on their foot. Of course, chemists are quite familiar with pure alcohol, and network technicians and programmers are familiar with TCP, UDP, and IP.
The familiar smell of alcohol, that you can detect to some degree in nearly everything containing alcohol — that’s DNS.
NSA Certified
February 27, 2014
The world of computing has a huge problem with surveillance. Whether you blame the governments doing it or the whistleblowers revealing it, the fact is that consumer adoption and satisfaction is being inhibited by an entirely-justified lack of trust in the systems.
Here’s how the NSA can fix that, increase the safety of Americans, and, I suspect, redeem itself in the eyes of much of the country. It’s a way to act with honor and integrity, without betraying citizens, businesses, or employees. The NSA can keep doing all the things it feel it must to keep America safe (until/unless congress or the administration changes those rules) and by doing this additional thing it would be helping protect us all from the increasing dangers of cyber attacks. And it’s pretty easy.
The proposal is this: establish a voluntary certification system, where vendors can submit products and services for confidential NSA review. In concluding its review, the NSA would enumerate for the public all known security vulnerabilities of the item. It would be under no obligation to discover vulnerabilities. Rather, it would simply need to disclose to consumers all the vulnerabilities of which it happens know, at that time and on an ongoing basis, going forward.
Vendors could be charged a reasonable fee for this service, perhaps on the order 1% gross revenue for that product.
Crucially, the NSA would accept civil liability for any accidental misleading of consumers in its review statements. Even more important: the NSA chain of command from the top down to the people doing the review would accept criminal liability for any intentionally misleading statements, including omissions. I am not a lawyer, but I think this could be done easily by having the statements include sworn affidavits stating both their belief in these statements and their due diligence in searching across the NSA and related entities. I’m sure there are other options too.
If congress wants to get involved, I think it might be time to pass an anti zero day law, supporting NSA certification. Specifically, I’d say that anyone who knows of a security vulnerability in an NSA certified product must report it immediately to the NSA or the vendor (which must tell each other). 90 days after reporting it, the person who reported it would be free to tell anyone / everyone, with full whistleblower protection. Maybe this could just be done by the product TOS.
NSA certified products could still include backdoors and weaknesses of all sorts, but their existence would no longer be secret. In particular, if there’s an NSA back door, a cryptographic hole for which they believe they have the only key, they would have to disclose that.
That’s it. Dear NSA, can you do this please?
For the rest of you, if you work at the kind of company the Snowden documents reveal to have been compromised, the companies who somehow handle user data, would you support this? Would your company participate in the program, regaining user trust?
Fix 303 with client-side redirects
April 6, 2012
I am trying to stay far away from the current TAG discussions of httpRange-14 (now just HR14). I did my time, years ago. I came up with the best solution to date: use “303 See Other”. It’s not pretty, but so far it is the best we’ve got.
I gather now the can of worms is open again. I’m not really hungry for worms, but someone mentioned that the reason it’s open again is that use of 303 is just too inefficient. And if that’s the only problem, I think I know the answer.
If a site is doing a lot of redirects, in a consistent pattern, it should publish its rewrite rules, so the clients can do them locally.
Here’s a strawman proposal:
We define an RFC 5785 well-known URI pattern: .well-known/rewrite-rules. At this location, on each host, the host can publish some of its rewrite and redirection rules. The syntax is a tiny subset of the Apache RewriteRule syntax. For example:
# We moved /team to /staff RewriteRule /team/(.*) /staff/$1 301 # All the /id/ pages get 303'd to the doc pages RewriteRule (.*)/id/(.*) $1/doc/$2 303
The syntax here is: comments start with a slash; non-comments have four fields, separated by whitespace. The first field is the word “RewriteRule”. The second is a regular expression. The third is a string with back-references into the regular expression. The fourth is a numeric redirect code. Any line not matching this syntax, or otherwise not understood by the client, is to be ignored.
Clients that do not implement this specification will function unchanged, not looking at this file. Clients that do implement this specification keep track of how many times they get an HTTP redirect from a given host. If they get three or more redirects during one small period of time (such as a minute, or one run of the client if the client is short-lived), they perform a GET on /.well-known/rewrite-rules.
If the GET succeeds, the result should be cached using normal HTTP caching rules. If the result is not cached, this protocol is less efficient than server-side redirects. If the result is cached too long, clients may see incorrect data, so clients must not cache the result for longer than permitted by HTTP caching rules. (Maybe we make an exception for simple-minded clients and say they MAY ignore cache control information and just cache the document for up to 60 seconds.)
If a client has a non-stale set of rewrite-rules from a given host, it should attempt to perform those rewrite rules client-side. For any GET, PUT, etc, it should match the URL (after the scheme name and colon) against the regular expression; if the match succeeds, it should perform the match-substitution into the destination string and use that for the operation, as if it had gotten a redirect (with the given redirect code).
As an example deployment, consider DBPedia. Everything which is the primary subject of a Wikipedia entry has a URL has the form http://dbpedia.org/resource/page_title. When the client does a GET on that URL, it receives a 303 See Other redirect to either http://dbpedia.org/data/page_title or http://dbpedia.org/page/page_title, depending on the requested content type.
So, with this proposal, DBPedia would publish, at http://dbpedia.org/.well-known/rewrite-rules this content:
RewriteRule /resource/(.*) /data/$1 303
This would allow clients to rewrite their /resource/ URLs, fetch the /data/ pages directly, and never going through the 303 redirect dance again.
The content-negotiation issue could be handle by traditional means at the /page/* address. When the requested media type is not a data format, the response could use a Content-Location header, or a 307 Temporary Redirect. The redirect is much less painful here; this is a rare operation compared to the number of operations required when a Semantic Web client fetches all the data about a set of subjects
My biggest worry about this proposal is that RewriteRules are error prone, and if these files get out of date, or the client implementation is buggy, the results would be very hard to debug. I think this could be largely addressed by Web servers generating this resource at runtime, serializing the appropriate parts of the internal data structures they use for rewriting.
This could be useful for the HTML Web, too. I don’t know how common redirects are in normal Web browsing or Web crawling. It’s possible the browser vendors and search engines would appreciate this. Or they might think it’s just Semantic Web wackiness.
So, that’s it. No more performance hit from 303 See Other. Now, can we close up this can of worms?
ETA: dbpedia example. Also clarified the implications for the HTML Web.
RDF Steps Carefully Forward
April 14, 2011
18 months ago, when Ivan Herman and I began to plan a new RDF Working Group, I posted my RDF 2 Wishlist. Some people complained that the Semantic Web was not ready for anything different; it was still getting used to RDF 1. I clarified that “RDF 2” would be backward compatible and not break existing system, just like “HTML 5” isn’t breaking the existing Web. Still, some people prefered the term “RDF 1.1”.
The group just concluded its first face-to-face meeting, and I think it’s now clear we’re just doing maintenance. If we were to do version numbering, it might be called “RDF 1.0.1”. This might just be “RDF Second Edition”. Basically, the changes will be editorial clarifications and bug fixes.
The adventurer in me is disappointed. It’s a bit like opening your birthday present to find nice warm socks, instead of the jet pack you were hoping for.
Of course, this was mostly clear from the workshop poll and the charter, but still, I had my hopes.
The most dramatic change the group is likely to make: advise people to stop using xs:string in RDF. Pretty exciting. And, despite unanimous support from the 14 people who expressed an opinion in the meeting, there has now been some strong pushback from people not at the meeting. So I think that’s a pretty good measure of the size change we can make.
As far as new stuff…. we’ll probably come up with some terminology for talking about graphs, and maybe even a syntax which allows people to express information about graphs and subgraphs. But one could easily view that as just properly providing the functionality that RDF reification was supposed to provide. So, again, it’s just a (rather complicated) bug fix. And yes, making Turtle a REC, but it’s already a de facto standard, so (again) not a big deal.
The group also decided, with a bit of disappointment for some, not to actively push for a JSON serialization that appeals to non-RDF-folks. This was something I was interested in (cf JRON) but I agree there’s too much design work to do in a Working Group like this. The door was left open for the group to take it up again, if the right proposal appears.
So, it’s all good. I’m comfortable with all the decisions the group made in the past two days, and I’m really happy to be working with such a great bunch of people. I also had a nice time visiting Amsterdam and taking long walks along the canals. But, one of these days, I want my jet pack.
Elevator Pitch for the Semantic Web
February 2, 2011
SemanticWeb.com invited people to make video elevator pitches for the Semantic Web, focused on the question “What is the Semantic Web?”. I decided to give it a go.
I’d love to hear comments from folks who share my motivation, trying to solve this ‘every app is a walled garden’ problem.
In case you’re curious, here’s the script I’d written down, which turned out to be wayyyy to long for the elevators in my building, and also too long for me to remember.
Eric Franzon of SemanticWeb.Com invited people to send in an elevator pitch for the Semantic Web. Here’s mine, aimed at a non-technical audience. I’m Sandro Hawke, and I work for W3C at MIT, but this is entirely my own view.
The problem I’m trying to solve comes from the fact that if you want to do something online with other people, your software has to be compatible with theirs. In practice this usually means you all have to use the same software, and that’s a problem. If you want to share photos with a group, and you use facebook, they all have to use facebook. If you use flickr, they all have to use flickr.
It’s like this for nearly every kind of software out there.
The exceptions show what’s possible if we solve this problem. In a few cases, through years of hard work, people have been able to create standards which allow compatible software to be built. We see this with email and we see this with the web. Because of this, email and the Web are everywhere. They permeate our lives and now it’s hard to imagine modern life without them.
In other areas, though, we’re stuck, because we don’t have these standards, and we’re not likely to get them any time soon. So if you want to create, explore, play a game, or generally collaborate with a group of people on line, every person in the group has to use the same software you do. That’s a pain, and it seriously limits how much we can use these systems.
I see the answer in the Semantic Web. I believe the Semantic Web will provide the infrastructure to solve this problem. It’s not ready yet, but when it is, programs will be able to use the Semantic Web to automatically merge data with other programs, making them all — automatically — compatible.
If I were up to doing another take, I’d change the line about the Semantic Web not being much yet. And maybe add a little more detail about how I see it working. I suppose I’d go for this script:
Okay, elevator pitch for the Semantic Web.
What is the Semantic Web?
Well, right now, it’s a set of technologies that are seeing some adoption and can be useful in their own right, but what I want it to become is the way everyone shares their data, the way all software works together.
This is important because every program we use locks us into its own little silo, its own walled garden
For example, imagine I want to share photos with you. If I use facebook, you have to use facebook. If I use flickr, you have to use flicker. And if I want to share with a group, they all have to use the same system
That’s a problem, and I think it’s one the Semantic Web can solve with a mixture of standards, downloadable data mappings, and existing Web technologies.
I’m Sandro Hawke, and I work for W3C at MIT. This has been entirely my own opinion.
(If only I could change the video as easily as that text. Alas, that’s part of the magic of movies.)
So, back to the subject at hand. Who is with me on this?
Can we use Lean Startup methods to build the Semantic Web?
January 28, 2011
I’m disappointed in the pace of development of the Semantic Web, and I’m optimistic that the Lean Startup ideas can help us move things along faster.
I’ve been a fan of Eric Ries and the Lean Startup ideas for while, but last night I was lucky enough to get to see him speak, and to chat with some other adherents. There are a lot of ideas here, but the bit that jumps out at me today is this, loosely paraphrased:
Reality distortion fields are bad. Instead of using charisma, style, and emotions to motivate your colleagues to act on faith, motivate them with experimental evidence.
I think we have scant evidence that the Semantic Web will work, and that most of us have been working on this as an act of faith. We believe, without solid evidence, that it can work and will be a good thing when it does. You could say we’re operating in an RDF (resource description framework) RDF (reality distortion field).
The Lean Startup methodology says that we should get out of that field as quickly as possible, doing the fastest experiments possible that will teach us what really works and does not work. On faith we can do 5+ year projects, hoping to show something interesting. Instead, we should be doing ❤ month projects to test a hypothesis about how this is all going to be useful.
It’s a shame that most of us are funded in ways that don’t support or reward this at all. It’s a shame the research funding agencies operate on such a glacial and massive scale; in many ways they seem geared more towards keeping people busy and employed than actually innovating and producing knowledge for the world.
Below are my notes taken during Eric’s talk. I have not cleaned them up at all, so you can see just how badly my fingers spell “entrepreneur” when my brain has moved on to something else. I believe slides and the talk itself are available on line; it’s a talk he often gives, so if you have the time, watch it instead of just skimming my notes. (eg this one at Stanford.) Someone else with much better formatting and spelling posted their notes from last night’s talk. You probably want to read them instead, and then come back here and share your insights with us.
$$ Thu Jan 27 18:20:41 EST 2011 ((( EricReis
2 yrs ago at Hobies in palo alto, 6 people, first talking about this...
silicon valley is parochial, rarely getting out of the bublle.
#leanstartup
new conversation -- what is entrepreneurship.
strsaight from unhear of to overhypes, without people having learned about it.
put entreneurship on a more solid footing.
What is a startup?
A startup is a human institution deseigned to delivera a new
product or service under conditions of extreme uncertainty.
Nothing to do with size of company, sector of the economigy, or
industry.
ALL THE BORING STUFF, and how to get better at it.
Startup = Experiment
Web 2.0 chart --- lots failed at 3 years.
they all failed for BAD reasons.
and how many really lived up to their potential....???!!! SO FEW.
"If you do everything I did, you can fail like I did."
We need a giant industrial support group.
"Hi, I'm eric, and most of my startups failed."
It's all Taylor's fault. :-)
father of scientific management.
1911. birth of management
"In the past, the man was first. In the future, the system will be first."
"Work should be done efficiently"
"Work should be divided into tasks"
"It's possible to organize craftsmen"
Management by exception -- only have them report their exceptions.
Now, decomposing work into tasks is 100 years old.
Everything in this room was constructed under the supervision of managers trained by Taylor and his disciples.
Shadow Beliefs:
* We know what customers want (reality distortion field)
* We can accurately predict the future
just dont believe the hockey stick spreadsheet
* Andvancing the plan is progress
eg keep everyone busy, write code, do your functional job!
-- if we're building something no one wants, is it progress!
[[ NO -- real progress is LEARNING ]]
The Lean Revolution (Lean Manufacturing)
W E Demming, Taiichi Ohno
it's not Tim Quality Money -- pick two
we can get all three by being customer focused.
Agile Development
Alas, Agile development comes out big IT departments.
works IF you know what the customer really needs.
Steve Blank.
Customer Development
Agile (Product) Development
imvu story
im networks -- join them all.
he wrote this, in 6 months, to ship to customers.
5 years before that.
had to pivot to standalone network.
GREAT code, but no one wanted it.
claim to have learn something -- about to get fired. :-)
learning is a 4 letter word in management
-- bad plan -- fired
-- failure to execute -- fired
Ask yourself: IF my goal was to learn this, could I have done this
without writing the code?
YES --- just make the landing page!!!
As an entrepreneur, you NOT LONGER HAVE a FUNCTIONAL DISCINPINE.
you do whatever you need to to get there
Entreprenursip is management
+ OUR GOAL is to create an institution, not just a product
* traditona lamangement preactices fail. (mba)
* nee entrepeurial managemt -- working under extreme uncertainyu
The Pivot --- SUDDENLY overhyped.
YOU MUST be able to do this. The successes can do this.
They can find the good ideas from the bad, inside the distortion field.
SPEED WINS.
how many pivots you have left.
if we can reduce the time betwwen pivts,
we can increas the odds of our success.
BUILD -> MEASURE -> LEARN
startup= turns ideas into code
IF YOU DIDNT BUILD ANYTHING, you cant pivot
IF YOU DIDNT TEST IT WITH CUSTOMERS, you cant pivot
MINIMIZE total time through the loop. Cycle time dominates.
gnl mgmt is about efficiency, not cycle time.
GOING THROUGH THE LOOP -- thats how you you settle arguments between founders.
How much design -- a reasonable balance.
FIVE principals.
-- entreps are everywhere
anywhere we seek out uncertainty
which is everywhere, given uncertainty from IT rev.
-- entrp is mgmt
-- validated learning
-- innovation accounting
normally just compliance reporting
but: drive accountablity -- hold mgrs accountable
GM = "std volume" to compute how many cars each division
is expected to sell. allows gm to give bonuses.
NOT good for entreps.
"success theater" (cumulative total registrations Heh.)
ACTIONABLE METRICS, per customer, NOT VANITY METRICS.
facebook per-customer behaviors were exciting. Customers were
heavily engaged in voluntary exchange with company. And very
viral.
NEED an accounting paradigm for entrps to prove
they've done validated learning.
so you never take credit for random stuff, but only
take credit for what you derve it for.
-- build measure learn
HOW do we know when to pivot?
as if it were obvious when there's a failure.
land of the living dead.
persevere straight into the ground.
Right answer: (acocunting)
pattern, like in science,
when the experiments are no longer very productive.
If When we can't move the needle very much.
Vision, Strategy, or Product
- what makes a great company?
500 Auto companies before Ford!!!
they didnt have the right process.
Vision doesnt change. it's about changing the world.
Strategy is how to build a business around that.
product dev == optimization
pivot is changing strategy, not vision.
THERE is not testing The Vision. We're NOT trying to
elimintate vision.
What should we measure? How do products grow?
Entrp. accounting
Are we creating value?
What's in the MVP?
- should a feature be in or out? Out.
Can we go faster?
NEW BOOK.
================================================================
lean.st/LeanStartupBos
startuplessonslearned
$$ Thu Jan 27 19:53:19 EST 2011
How do you keep engineers having faith in the process given MVP.
How to manage engineers under uncertainty?
1. Keep them calm. Heads down, cranking out code.
[reeks of frd taylor.]
2. Enlist all functions in process of discovering if on right track.
ABANDON Reality Distorion Field.
People will be way more creative if they know what's going on.
The truth will set you free.
================
Q: Newbie: use of the term "movement"
Eric: I dont want other people to to be doing this.
Eric: I used to be a coder. What do I do now???
there IS something going on worldwide. this is science, not religion.
lets be careful.
if it works for entrepreneur, it's part of Lean Startup.
We're learning a lot over the past two years.
The movement is not me -- the movement is you guys testing these ideas, in changing the world.
this is NOT about proprietary advantage.
Eric used to think the right way to change the world was get the VCs to
evangelize. Sooooo dumb of me.
vc: "im not that interested in improving the world, just my profolio"
But now, we should do science. If we all do it, we'll all improve the
world and live in a better world.
Q: how to test ideas people are not searching for.
eg dropbox -- no one knows they want it.
If customers dont know they have the problem and know the name of it,
you have to find a new way.
at imvu, people didnt know it "outbound is the new inbound" we did ad
compaigns, $5/day, buying keywords of every adjacent product, "*" +
chat. And drove people to our landing page. We wanted to learning
the differeences in convertion between these channels.
dropbox's MVP was a video, aimed at DIGG users. Drove people to
waiting list, beta users.
justin tv sl conf video
================
MBAs.
how much do MBAs need to re-learn?
er: I'm doing entreprenur in residence at harvard business school.
but why waste time with MBAs?
"what do people say about us when we're not in the room?"
MBAs have one big advantage: very process and discipline oriented.
if you dont have some failures, yo dont learn.
you need to be able to tell what change to the product/market caused
the numbers to change. IT HAS TO BE A VALID SCIENTIFIC EXPERIMENT.
================
Some new stuff:
the right things to measure are clear and consistent across all startups.
1. value test -- do you know it creates values
2. working enging of growth.
two feedback loops:
-- eg loop in cylendar engine, and driver-and-surroundings
write down how to get to work == taylor plan
three engines of growth
-- paid. you make a $1 per customer, and they cost $0.50 to buy
(have to be able to buy customers)
-- viral. as a necessary consequence of customer using it, they
get their friends to use it. "someone has tagged you in a photo"
you HAVE to click on that. even some fashion busineses.
they "grow themselves" bye xploiting bug in human naturo
-- sticky, engagment. addictive, network effects, lockin, ebay,
wotw, compounding interest. so small viral can compound it, if
sticky enough.
================
easily replicated product, get to market first?
fear: someone will steal my idea.
So: take your second best idea, and try to get someone to steal it.
TRY to get them to steal your idea. PEOPLE dont steal ideas.
IT SEEMS NUTS, BUT ITS TRUE.
You need a good idea.
Threat by big company to clone you -- they poached a co-founder --
came out with exacty product two years delayed. $100m failure for
them.
FIRST mover advantage is very rare in reality. (!!!)
================
one person from each company. how to get whole company to buy in?
people often say: that's a really great idea for someone else to do.
the issue is the WORK is a system. Your company is a perfect robust
system, stable. very very hard to change -- must be planned
carefully.
try to find one area where there is painful uncertainty, and say there
is a community of people trying science to solve this problem.
every nods at maximize speed through the loop.
BUT if you do that, you will MAKE PEOPLE FEEL INEFFICNENT. People
will be interrrupted to do things "not their job". There will be a
team powwow where people say they hate it making them less efficient.
NEED people bought into theory -- understanfing the value of VALIDATED
LEARNING. Only do this where you have authority, maybe just yourself.
================
How does Lean Startup affect managment & sales force. Lab Equipment
company. --- "sales people are whiners" Really, customers were giving
great feedback, and non of that was making it back to management.
4 steps to ephinary -- steve blanks book -- perfect on enterprise sales.
YOU CANNOT DELEGATE customer development. founders and senior mgmt
have to be in the room with the customers, at least some of the time.
Salespeople arent supposed to be good listeners.
Mgrs should DO THE SALES THEMSELVES. THe goal is not to make money,
it's to get validated learning....
ONCE we understand how to do the sales, THEN give it to the salesfolk,
as per Steve Blank.
if using sales force, you are doing Paid Engine Of Growth.
================
Q: I have a product that people havnts paid for. mainstream product.
personal keepsake. needs to look really good. hard to measure.
style counts. what's mvp in that scenario.
why cant you do a landing page.
keepsake book.
goal of MVP --- least amount of work to learn what needs to be
learned. such as whether customers will pay. eg get pre-orders.
you can always test demand through fake landing pages.
"Concierge" from food-on-the-table. did it all by hand, until they
figured out what folks REALLY wanted.
PEOPLE will not truthfully answer what they would do. "Would you buy
this" turns out to be TERRIBLE DATA.
**** YOU ALWAYS CAN TEST
requires VERY difficult risking rejections. CUSTOMER SERVICE HURTS!!!
* Eric *HATEs* customer feedback *
does he really want to know what you thought about today's talk? No!!!
================
When collective feedback, its NOT ABOUT YOU, it's about the person
giving it to you.
"product is okay" means "product sucks but I'm polite"
================
very very hard. but rewards are emense.
think about all the people utterly wasting their time.
let's redeem them; make it happen!.
$$ Thu Jan 27 20:35:27 EST 2011 )))
Explaining Linked Data
June 8, 2010
I’m going to try explaining linked data again, tonight, at the Cambridge Semantic Web Gathering. I will attempt to keep it simple, while still covering the important details. We’ll see how it goes.
My slides, for people who want a peek ahead of time, are here.
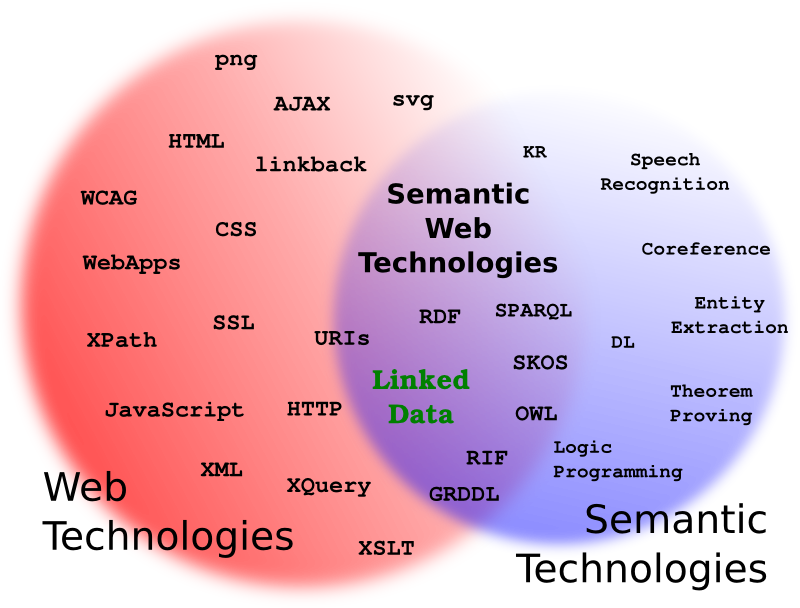
ETA: Thanks to Marco Neumann, there’s a video of my talk. I’m pretty happy with it. Also, my Venn Diagram slide, which you’re welcome to re-use with credit.
From JSON to RDF in Six Easy Steps with JRON
June 4, 2010
Sometimes, if you stand in the right place and squint, JSON and RDF line up perfectly. Each time I notice this, I badly want a way to make them line up all the time, no matter where you’re standing. And, actually, I think it’s pretty easy.
I’ve seen a few proposals for how to work with RDF data in JSON, but the ones I’ve seen put too much burden on JSON folks to accomodate RDF. It seems to me we can let JSON keep doing what it does so well, and meanwhile, we can provide bits of RDF which can be adopted when needed. Instead of pushing RDF on people, allow them to take the parts they find useful.
In thinking about it, I’ve come up with six things RDF can do that are not standard parts of JSON. These are things one can do with JSON, of course, but not in any standard way. My suggestion is these bits of functionally be provided in an RDF-compatible way (as I detail below), so that the JSON world and the RDF world can start to really play well together.
I’m interested to hear what people think of this. Blog comment, email to sandro@hawke.org (maybe cc semantic-web@w3.org?), or catch me in the halls at SemTech. I expect this general topic of RDF-meets-JSON will be discussed at the RDF Next Steps workshop, and if the stars line up right, maybe we can get a W3C Recommendation in this space in the next year or so. Let’s call this particular proposal JRON 0.1 (Javascript RDF Object Notation), not “Sandro’s Proposal”, so I can be freer to like other designs and be properly neutral.
Step 0: Start with ordinary JSON
In general, JSON and RDF are very similar, although they are usually described using different terminology. Of course, they both have strings and numbers. They both have way of encoding a sequence of items: arrays in JSON, lists in RDF (some details below). The main structuring is around key-value pairs, which JSON calls an ‘object’. In RDF we call it the “subject” and focus on its connection with each key-value pair; the three together form an RDF triple.
The point here is that ordinary JSON structures correspond to an important subset of RDF. The don’t exactly match that subset because RDF uses namespace, as detailed in step 5 below. The other steps below show the ways in which JSON is a subset of RDF. If one takes all the steps here, using JSON with these conventions, one has full RDF.
So, here are the steps. Steps 1-3 are pretty simple and not very interesting. They address everyday concerns in data processing. Steps 4-6 may be a little more surprising if you’re not familiar with RDF.
Step 1: Allow Extended Datatypes
Why: For datatypes, JSON only has strings, numbers, booleans. Sometimes people want to store and manipulate other datatypes, such as dates, or application-specific datatypes.
How: RDF uses XML’s datatype mechanism, where data values are conveyed as a pair of items: a lexical representation (a sequence of characters) and a datatype identifier (a sequences of characters which happens to be a URI). Each datatype is a mapping from strings (lexical representations) to values; the datatype identifier tells us which datatype is to be used to interpret this particular representation.
In JRON, we represent this pair like this:
{ "__repr": "2010-03-06",
"__type": "http://www.w3.org/2001/XMLSchema#date" }
You can put this as a value in a list or in a key-value pair, just like a string or number.
RDF doesn’t restrict which datatypes are used. Some recent standards work selected this list as the set people should implement.
Personally, I’m not sure users need to be able to extend datatypes. I see dates being important, but otherwise I’m not convinced. Still, it’s in RDF, and I like compatibility, so it’s here.
Step 2: Allow Language Tags
Why: When you have text available in several different languages, language tags provide a way to select which of the available strings, if any, matches the language preference of the user.
Also: Text-to-speech systems can handle text better if they know which natural language to use in pronouncing the text.
How: RDF allows language tags on string literals. In JRON, we use a pair like this:
{ "__text": "chat",
"__lang": "fr" }
Commentary: Personally, I’ve never liked this bit of RDF. I feel like there are better architectures for handling language tagging. But there was a vocal community that felt this was essential, so it’s in the standard. I gather some people like it, and I haven’t seen a good counter-proposal.
Step 3: Allow Non-Tree Structures
Why: Sometimes your data is not tree structured. Sometimes you have an arbitrary directed graph, such as when representing a social network.
How: In RDF, an arbitrary “node id” is available for making non-tree structures. We can do the same in JRON, saying any object may have a node id, and if it does, the object is considered the same as all other objects with the same node id. Like this bit JSON saying my friend Eric and I both know each other:
...
{ "foaf_name": "Sandro Hawke",
"foaf_knows: { "__node_id": "n102" },
"__node_id": "n334" }
...
{ "foaf_name": "Eric Prud'hommeaux",
"foaf_knows: { "__node_id": "n334" },
"__node_id": "n102" }
...
In the above example, the objects representing me and Eric are given node ids, and then those node ids are used to make the links to each other. We could also do this with only one node id, but we still need at least one:
{ "foaf_name": "Sandro Hawke",
"foaf_knows: { "foaf_name": "Eric Prud'hommeaux",
"foaf_knows: { "__node_id": "n334" },
"__node_id": "n334" }
Okay, those were the ordinary three things to add to JSON. Here are the interesting three:
Step 4: Allow Cross-Document Structures
Why: Sometimes, there is useful, relevant data available on the Web but it’s not part of the current JSON document. We would not want all the Web pages in the world to be gathered into one big Web page; similarly, it’s good to keep data in different documents. But that shouldn’t stop us from easily combining the data, and keeping the links intact.
How: RDF allows IRIs (unicode web addresses) to be used as node identifiers. They are like node ids, except they work across multiple documents; they are globally unambiguous identifiers, and systems can use Web protocols to dereference them to get other useful information.
In JSON, we can do this:
{ "foaf_name": "Sandro Hawke",
"__iri": "http://www.w3.org/People/Sandro/data#Sandro_Hawke"
}
Commentary: So why do we still need __node_id? Because sometimes it’s a pain to make up a good IRI. Some people prefer to always use IRIs, avoiding node_ids in their data, and that’s fine.
Step 5: Put Keys in Namespaces
Why: When data is coming from different sources across the Web, it’s not practical to get all the sources to agree on all the terminology. Instead, by using Web addresses (URLs/IRIs) as our keys, we allow individuals and organizations to make their own decisions. They can decide how much to share their vocabularies, and they avoid accidental name collisions. The web address also provides a handy link to documentation, community sites, schemas, etc.
How: It’s awkward to use a whole, long http IRIs everywhere, so as in many RDF syntaxes, JRON has a prefix expansion mechanism, like this:
{ "foaf_name": "Sandro Hawke",
...
"__prefixes": {
"foaf_" : "http://xmlns.com/foaf/0.1/"
}
}
Here the key “foaf_name” gets expanded into “http://xmlns.com/foaf/0.1/name”, which serves as a unique-on-the-Internet identifier for a particular conceptualization of names.
Commentary: Although I’ve left it almost to the end, this is the one mandatory part of this proposal. All the other elements are only present when required by the data. The null JRON document is: {“__prefixes”:{}}
Others have suggested this part can be optional, too, by having a set of standard prefixes for a given API. I’m not entirely opposed to that, but I’m concerned about how those defaults would be communicated in practice.
Also, I’m not sure there’s consensus on what character to use in the short name: should it be foaf_name, foaf.name, foaf:name, or what? The mechanism here is that you can use whatever you want: the __prefixes table keys are matched longest-first. If there’s an entry with an empty string, that provides a default namespace.
Step 6: Allow Multiple Values Per Key
Why: Sometimes it makes sense to have more than one value for some property. For instance, as it turns out, I have more than one friend. I could use a single-value ‘list-of-friends’ property, but sometimes it makes more sense to use a ‘friend’ property that has multiple values. In particular, if we’ll be learning who my friends are from multiple sources, and we were using lists, what order would we put the resulting combined list in?
How: We still just use JSON lists, but we indicate that the order does not matter, so the values can be merged arbitrarily:
{ "foaf.name": "Sandro Hawke",
"foaf.knows: { "__values": [
{ "foaf.name": "Eric Prud'hommeaux" },
{ "foaf.name": "Dan Brickley" },
{ "foaf.name": "Matt Womer" }
]}
}
Closing Thoughts
That’s it. Those are the six things that RDF does that normal JSONdoesn’t do. Did I miss something?
The API I’m imagining (but haven’t built yet) would have a few
features like:
- jron_reprefix(tree, desired_prefixes)
- Returns another JRON tree with all the prefixes matching the ones provided here. If you’re going to use foaf, for instance, you probably want to set a prefix like “foaf.” for foaf, so your code can expect it.
- jron_merge_nodes(tree) and jron_treeify(tree)
- convert a tree (suitable for transmitting) from/to a graph (suitable for use in memory
- jron_use_native_type(tree)
- Would convert all the __type/__repr objects into suitable local objects, if they exist. Maybe even date/time objects, if there’s a suitable library installed for those.
One technical issue for RDF folks:
Should JSON arrays be considered RDF Lists or RDF Sequences? Perhaps they default to RDF Lists but there can be an option flag in the top-level object:
{ ...
"__json_array_is_rdf_seq": true
...
}
When that flag is absent or false, arrays would be considered RDF Lists. My sense is no one needs to use both. Maybe soon we’ll know if RDF Sequences can finally be deprecated.

{kind=link}